An introduction to community detection problem with a view from matrix factorization.

Network data is presented everywhere nowadays, such as network of friends on social media, network of bees, networks of proteins. While these networks are very large and complex, their underlying structure could be seen as a set of a small groups call communities. Discovering these communities from a complex networks brings out essential characteristics of the networks, which is an important task for data analysis and exploration. Community detection problems aims at finding out membership of all nodes in a given network.
In this article, we cover how this problem is modeled using matrices, and dealt with using matrix factorization techniques.
Model and Problem Statement
We assume that there are $K$ distinct communities. Each node has a membership vector that indicates its membership with respect to these communities. This can be represented using a nonnegative vector $\textbf{m} \in \mathbb{R}^{K}$ where $0\leq m_i \leq 1$, and $\sum_{i} m_i = 1$.
A simple scenario is that a node can only belong to a single group. This happens for example in classification problem, where each item has a single class label.

But different from classification problem, we only observe interactions among nodes. Particularly, nodes within a community have similar chances of being connected to each other in compared to a connection among nodes of different communities. These connections are expressed as the edges of the network, and can be directional, un-directional, unweighted, or weighted, depending on particular model and dataset.
Consider a simple case of un-directional, unweighted edges. Then an edge between two nodes $i$ and $j$ is modeled as a Bernoulli random variable, \(a_{ij} \sim \text{Bernoulli}(p_{ij}),\) where parameter $p_{ij}$ is reflected by
- Membership of the two nodes belong to the same groups.
- The inherent interaction among groups.
One of the well-known models named Mixed-Membership Stochastic Blockmodels [1] assumes
\[p_{ij} = \textbf{m}_i^{\sf T} \textbf{B} \textbf{m}_j.\]The matrix $\textbf{B} \in \mathbb{R}^{K \times K}$, which is assumed to be symmetric models the inter-interaction among groups. A diagonal dominant $\textbf{B}$ models a network where nodes within a group tends to interact with each other much more often than interacting with a node outside of the group. For instance, memberships within the robotics club tend to have more connections to each other, maybe because they share the same interest, and have more common courses in their study, than the connections to students in the literature club. Although these connections are possible, they are rare.
On the other hand, a off-diagonal dominant matrix $\textbf{B}$ models a network where group memberships has little interaction but interacting more to outsiders. This happens naturally to for example bipartite network. For instance, a network of soccer players and their clubs.
A node can belong to a single community, or to simultaneously multiple communities. Elements in the membership vector for each node indicates how strongly the node belongs to certain groups. Specifically, $m_i=1$ and $m_j=0$ for all $j\neq i$ indicates that the nodes only belongs to the $i$-th community. In general, a node can belong to different communities with different level of association.
We are assuming that a network of $N$ nodes and $v$ edges are generated as follows. Node $i$ has an inherent membership vector $\textbf{m}_i \in \mathbb{R}^{K}$, where $m_i \geq 0, \textbf{1}^{\sf T}\textbf{m} = 1$. Collections of these nodes is presented as matrix $\textbf{M} \in \mathbb{R}^{N \times K}$. An edge between node $i$ and node $j$ is established depending on the interaction between these 2 nodes. Particularly, it is modeled as a Bernoulli distribution: \(A_{ij} \sim \text{Bernoulli}(\textbf{m}_i^{\sf T} \textbf{B} \textbf{m}_j).\)
Problem statement: Given the binary matrix $\textbf{A} \in \mathbb{R}^{N \times N}$ which also represents a un-directional, unweighted network, could we recover the membership of all nodes in that network?
Some Hints
There are at least two challenges in recovering $\textbf{M}$. Firstly, assuming $\textbf{P} = \textbf{M}^{\sf T} \textbf{B} \textbf{M}$ is observed, can we estimate $\textbf{M}$? And secondly, the task is even more challenging since $\textbf{P}$ is unobserved. Instead, we only have access to a binary matrix $\textbf{A}$ which is a very rough approximation of $\textbf{P}$.
Fortunately, a key finding in [2] reveals that knowing $\textbf{A}$ could reveal information about range space of $\textbf{M}$. Specifically, denote $\widetilde{\textbf{V}} \in \mathbb{R}^{K \times N}$ as $K$ leading eigenvectors of $\textbf{A}$, and $\textbf{V} \in \mathbb{R}^{K \times N}$as the $K$ leading eigenvectors of $\textbf{P}$, then Lemma 1 in [2] implies that
\(\widetilde{\textbf{V}} \approx \textbf{V} \textbf{O},\)
for some orthogonal matrix $\textbf{O}$.
Using simulated data, we can verify this statement empirically. We measure the difference of $\widetilde{\textbf{V}}$ and $\textbf{V}$ in terms of angle between 2 subspaces via the command subspace in Matlab and show the result in the following figure.
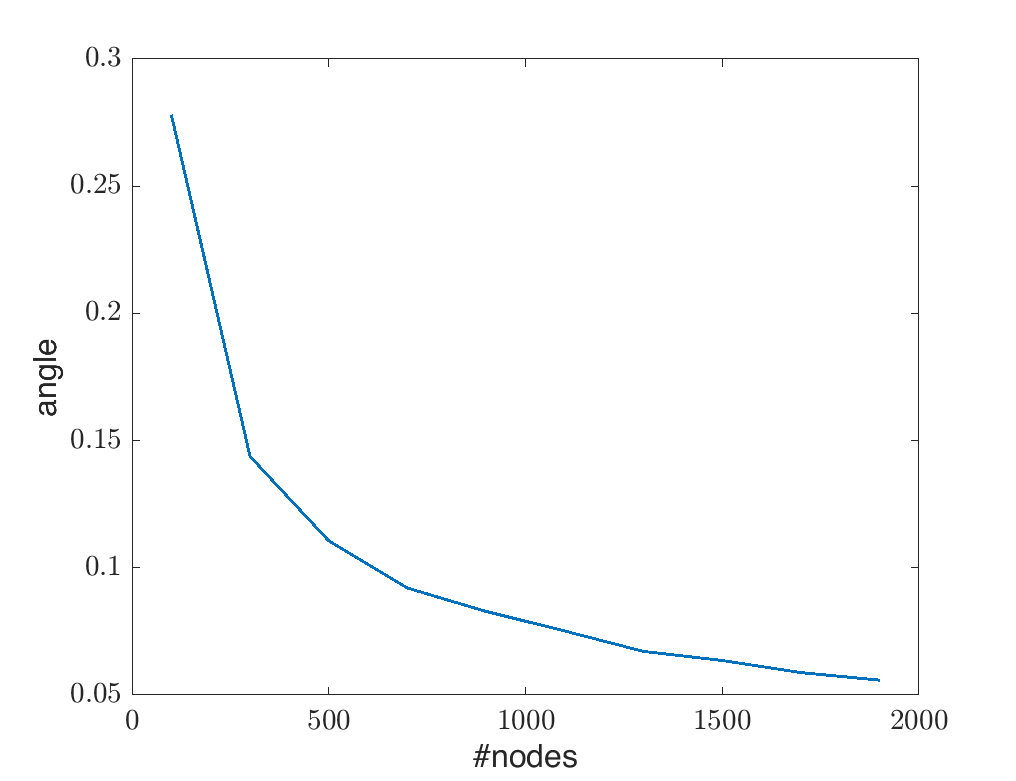
As you can see, as number of nodes increases, the angle between $\widetilde{\textbf{V}}$ and $\textbf{V}$ is smaller. That implies that with enough number of nodes, we can represent
\[\widetilde{\textbf{V}} = \textbf{M} \textbf{F} + \textbf{N},\]where $|| \textbf{N} | |_{\text{F}}$ is small.
Then the task boils down to estimating $\textbf{M}$ given $\textbf{V}$ following the above model. In general, this is an NP-hard problem. The issue arises because problem (x) could be multiple solutions. To see this, considering the ideal case where $\textbf{N} = 0$. Then there is no distinction between 2 different solutions $\textbf{M}$ and $\textbf{M} \textbf{Q}$ where $\textbf{Q}$ is some non-singular matrix.
The so-called separability condition has been proposed and widely used to guarantee that problem [x] has unique solution. In the context of community detection, it assumes the existence of a ‘pure node’ for each community. A pure node is a node that only belongs to a single community.
With the assumption of separability on $\textbf{M}$, given $\widetilde{\textbf{V}}$ we can find $\textbf{M}$, as suggested in [2,3,4].
Algorithm
Given observation $\textbf{A}$, we first perform eigendecomposition on the binary $\textbf{A}$ to get top $k$ eigenvectors to construct $\widetilde{\textbf{V}}$. Then we can recover $\textbf{F}$ using one of the NMF methods such as SPA, FastGradient [4], MERIT [3]. For demonstration, we employed MERIT in this article.
Having $\textbf{F}$, we can finally determine the membership matrix $\textbf{M}$ by solving a constrained LS problem
\[\begin{align} &\min_{\textbf{M}} \quad || \widetilde{\textbf{V}} - \textbf{M}\textbf{F} ||_{\rm F} \\ &\text{subject to } \quad \textbf{1}^{\sf T} \textbf{M} = \textbf{1}, \textbf{M} \geq 0 \end{align}\]Result
We generated a network of $N=100$ nodes, each node’s membership respect to $K=3$ communities following a Dirichlet distribution with parameter $0.2 \times \textbf{1}_3$. The observation $\textbf{A}$ is drawn from the Bernoulli distribution and it defines an un-directional, unweighted network. The results are shown below.

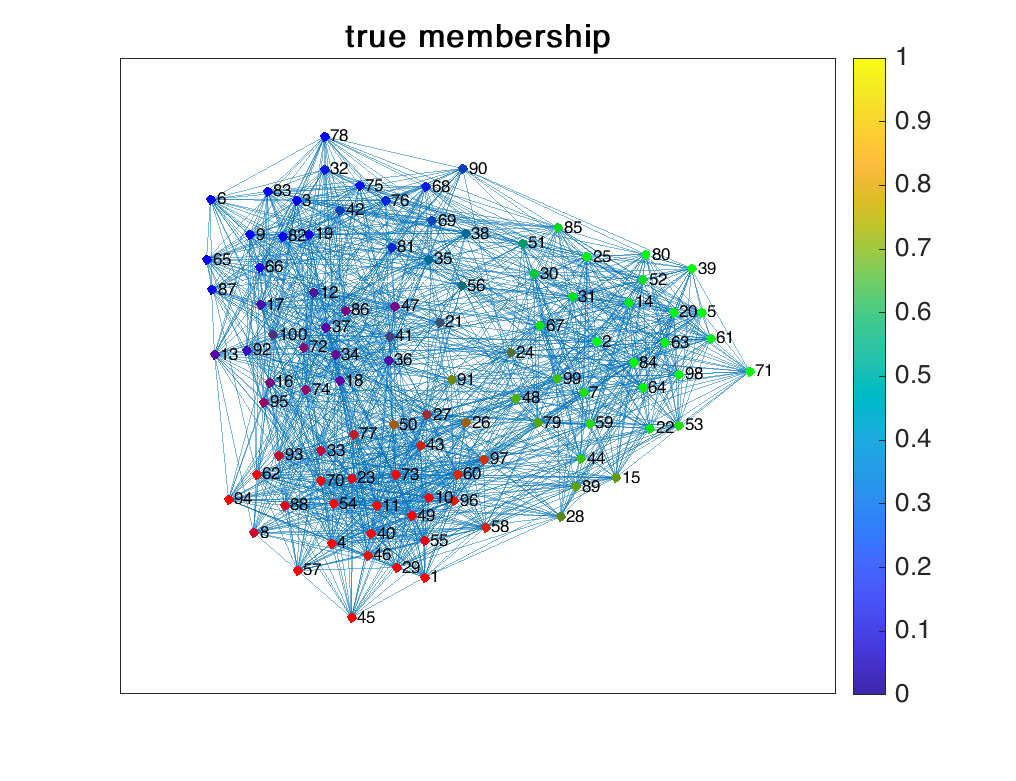
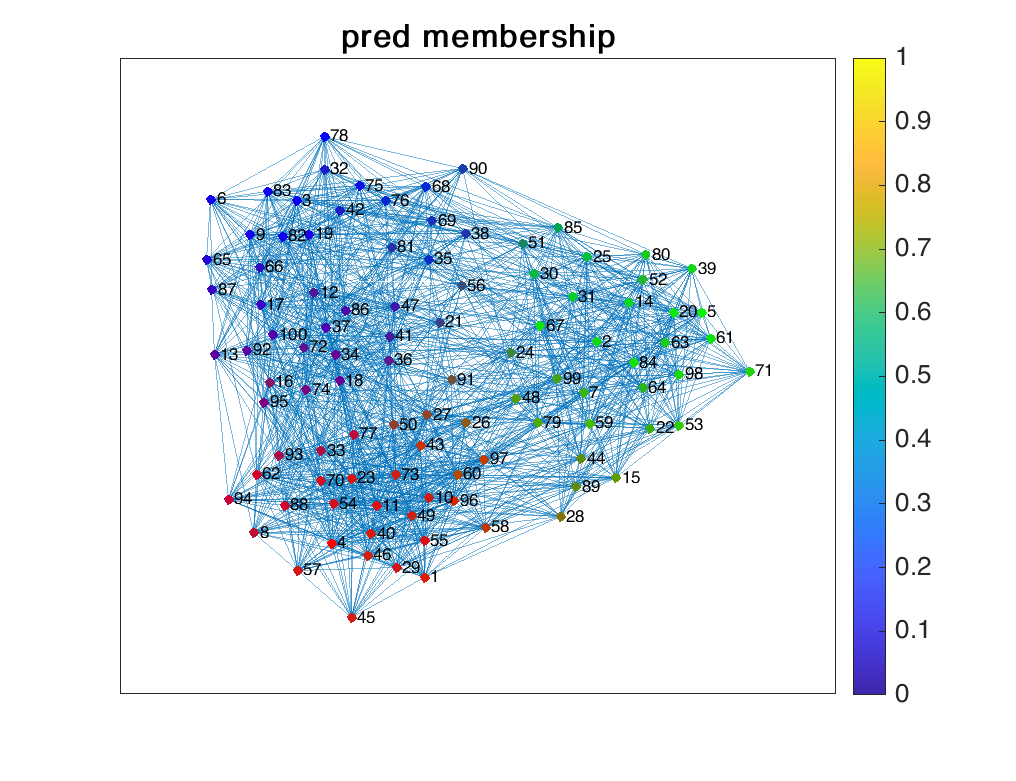
References
- [1] Airoldi, Edo M., et al. “Mixed membership stochastic blockmodels.” Advances in neural information processing systems 21 (2008).
- [2] Panov, Maxim, Konstantin Slavnov, and Roman Ushakov. “Consistent estimation of mixed memberships with successive projections.” Complex Networks & Their Applications VI: Proceedings of Complex Networks 2017 (The Sixth International Conference on Complex Networks and Their Applications). Springer International Publishing, 2018.
- [3] Nguyen, Tri, Xiao Fu, and Ruiyuan Wu. “Memory-efficient convex optimization for self-dictionary separable nonnegative matrix factorization: A Frank–Wolfe approach.” IEEE Transactions on Signal Processing 70 (2022): 3221-3236.
- [4] Gillis, Nicolas, and Robert Luce. “A fast gradient method for nonnegative sparse regression with self-dictionary.” IEEE Transactions on Image Processing 27.1 (2017): 24-37.