We have readings on the trendy LLM. I collected some papers myself here. The list is still updating
Attention/Transformer
The goal is to encode an sequential data: $x_1 \to x_2 \to \ldots \to x_t$.
As usual, since $x_i$ is discrete, $x_i \in \mathcal{V}$. Each $v \in \mathcal{V}$ is represented as a trainable vector. In Transformer, this vector is partitioned into 3 disjoint parts:
- $\textbf{q} \in \mathbb{R}^{d_k}$
- $\textbf{k} \in \mathbb{R}^{d_k}$
- $\textbf{v} \in \mathbb{R}^{d_v}$
This way, a sentence is encoded by 3 matrices $\textbf{Q} \in \mathbb{R}^{t \times d_k}, \textbf{K} \in \mathbb{R}^{t \times d_k}, \textbf{V} \in \mathbb{R}^{t \times d_v}$.
Next idea: the presentation of $x_i$ is a convex combination of other $\textbf{x}_j$ where $j=1, \ldots , i-1$. The presentation is realized by $\textbf{v}_i$, so \(\text{atten}_i(\textbf{v}_i) = \sum_{\ell =1}^{i} a_\ell \textbf{v}_\ell = \textbf{a}^{\sf T} \textbf{V}, \quad \textbf{a} \in \mathbb{R}^{t}\)
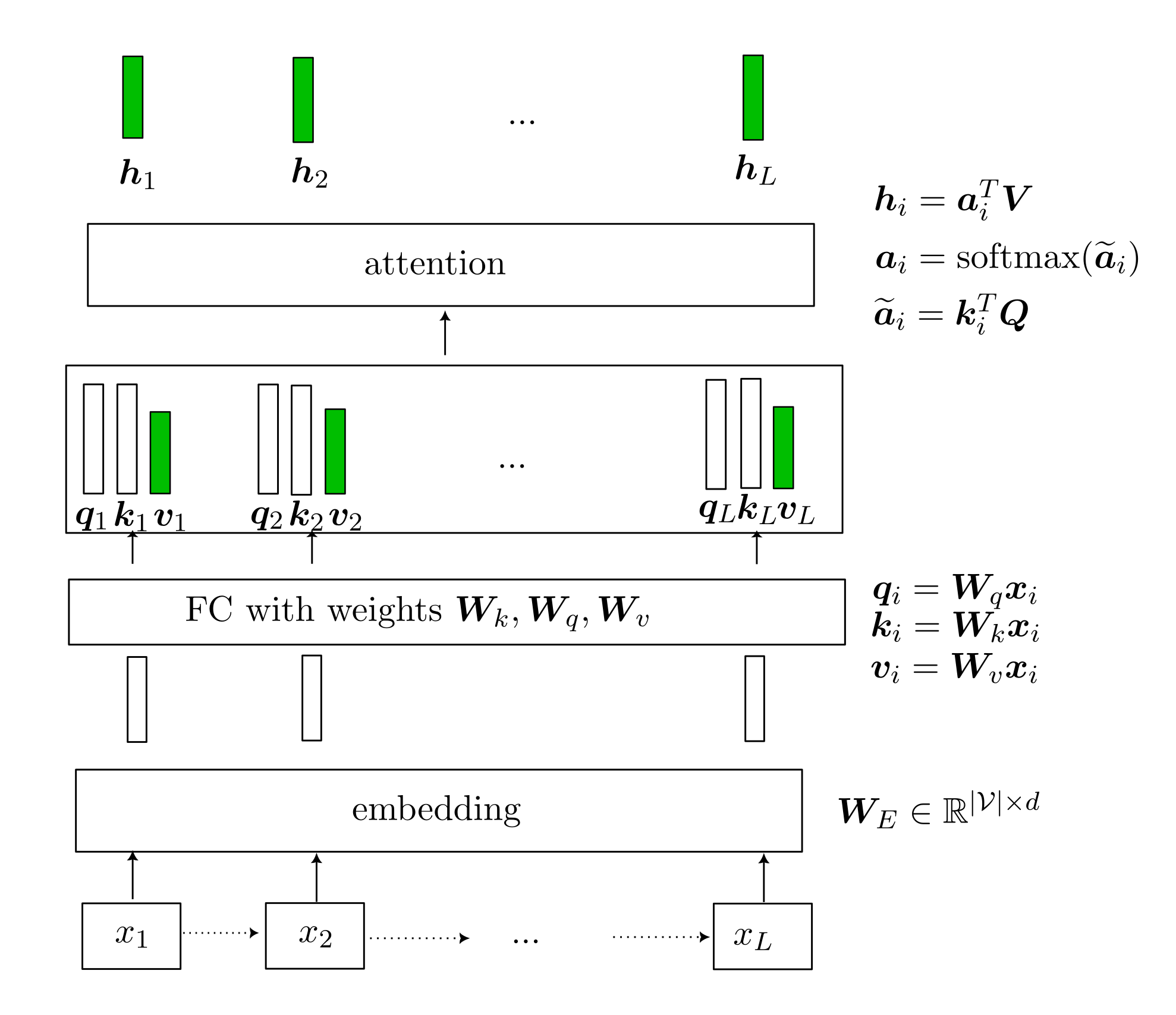
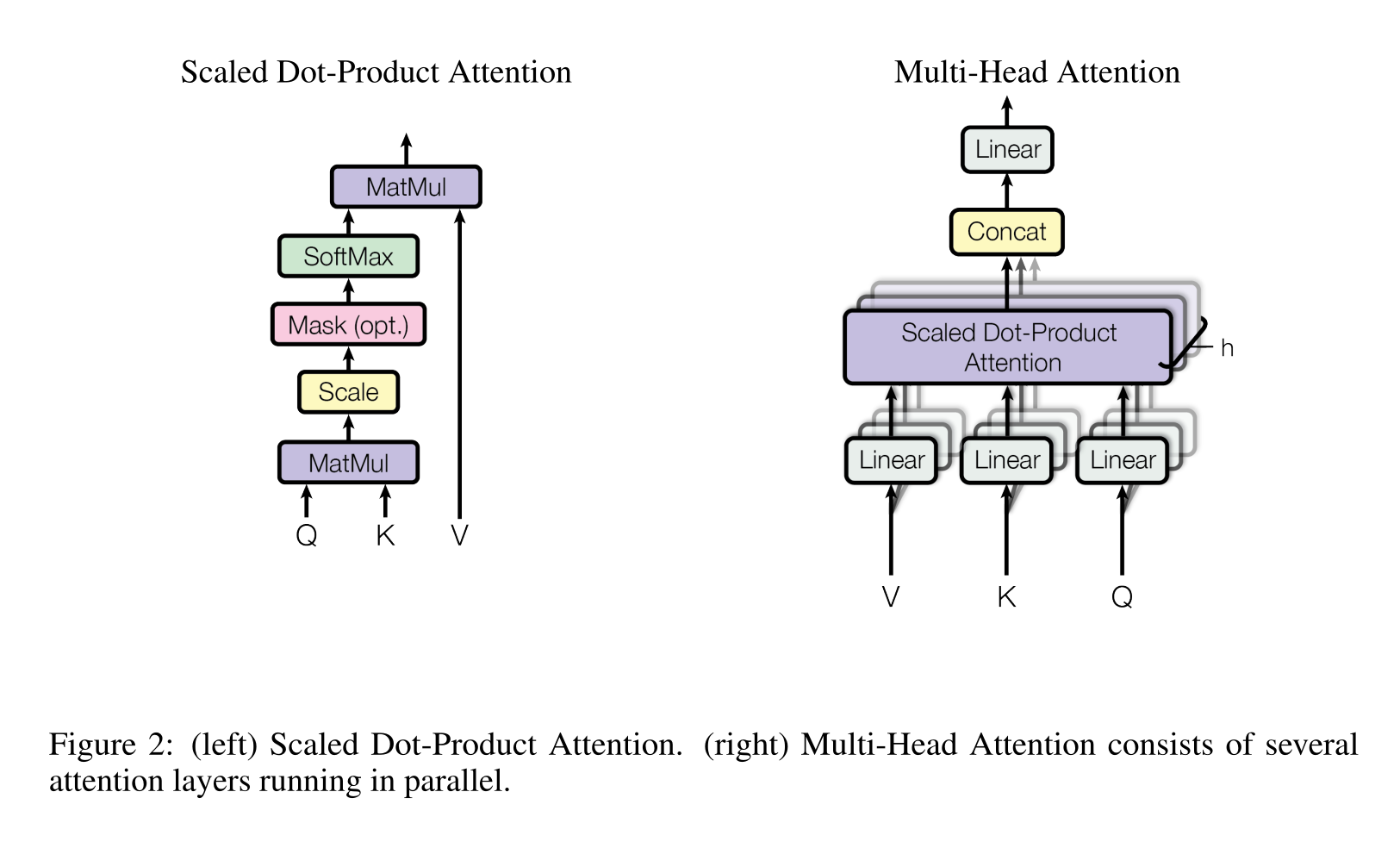
Now the coefficient $a_i$ must be learned somehow. Attention suggests that \(\begin{align*} &\widetilde{\textbf{a}}_i = [\widetilde{a}_1, \ldots , \widetilde{a}_t] = [\textbf{q}_i^{\sf T} \textbf{k}_1, \ldots , \textbf{q}_i^{\sf T} \textbf{k}_\ell, \ldots , \textbf{q}_i^{\sf T} \textbf{k}_t] = \textbf{q}_i^{\sf T} \textbf{K} \\ &\widetilde{\textbf{A}} = [\widetilde{\textbf{a}}_1, \ldots , \widetilde{\textbf{a}}_t] = [\textbf{q}_1^{\sf T} \textbf{K}, \ldots , \textbf{q}_t^{\sf T} \textbf{K}] = \textbf{Q}^{\sf T} \textbf{K} \\ &\textbf{A} = \text{softmax} (\widetilde{\textbf{A}}) \triangleq [\text{softmax}(\widetilde{\textbf{a}}_i), \ldots , \text{softmax}(\widetilde{\textbf{a}}_t)] \in \mathbb{R}^{t \times t} \end{align*}\) Each vector $\textbf{a}_i$ represent distribution of “attention” of word $i$ paying over the whole sentence.
So take everything as matricies, we have \(\begin{align*} \text{attention} &= \textbf{A}^{\sf T} \textbf{V}, \quad \textbf{A} \in \mathbb{R}^{d_v \times t} \\ &= \text{softmax}(\textbf{K}^{\sf T} \textbf{Q}) \textbf{V} \in \mathbb{R}^{t \times d_v} \end{align*}\)
Multiheads
Then, in order to allow for multiple learned patterns, each word is now presented with $H$ different triples $(\textbf{Q}_h, \textbf{K}_h, \textbf{V}_h)$. \(\text{attention} (\textbf{Q}\textbf{W}_h^{(1)}, \textbf{K}\textbf{W}_h^{(2)}, \textbf{V}\textbf{W}_h^{(3)}), \quad h=1, \ldots , H\) Then as usuall, every thing is concatenated and input to a final FC layer.
Motivation:
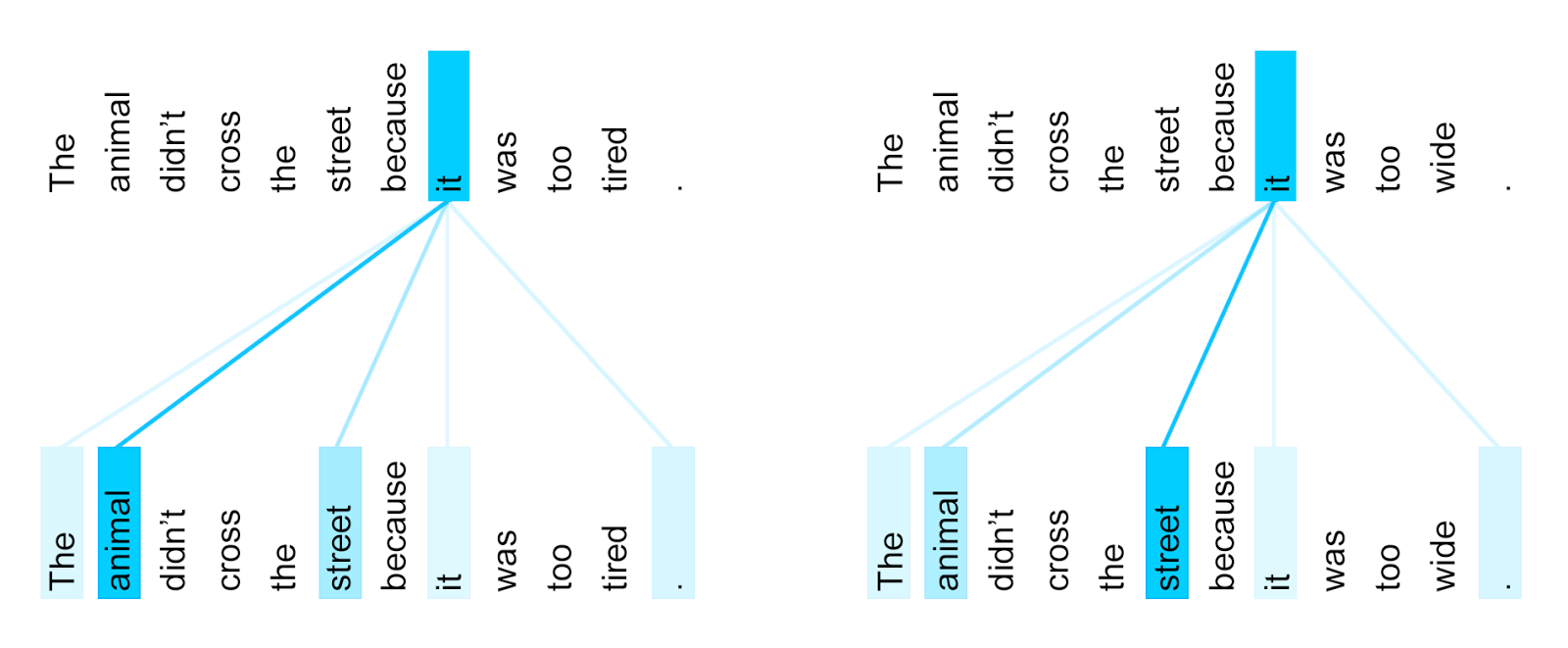
Order Encoding
Now as the representation is just a convex combination of some set, there is no notion of order. Hence it is necessary that the order info is encoded in the $\textbf{v}$ vector.

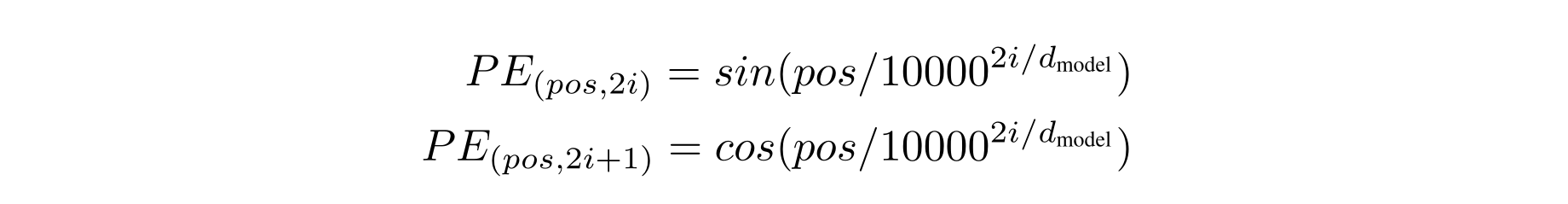
So that’s basically it.
![]()
Flamingo: a visual language model for few-shot learning

Task:

Mixing text and image, predict next word token, pretrained LLM, vision input is undergone a pretrain feature extractor, then to a trainable network to produce a fixed length vector for each image/video input.
Dataset is crawl from webpage, image is replaced by special token
The vision module produce a fixed number of tokens. These tokens are treated as word tokens.
Method

Input example:

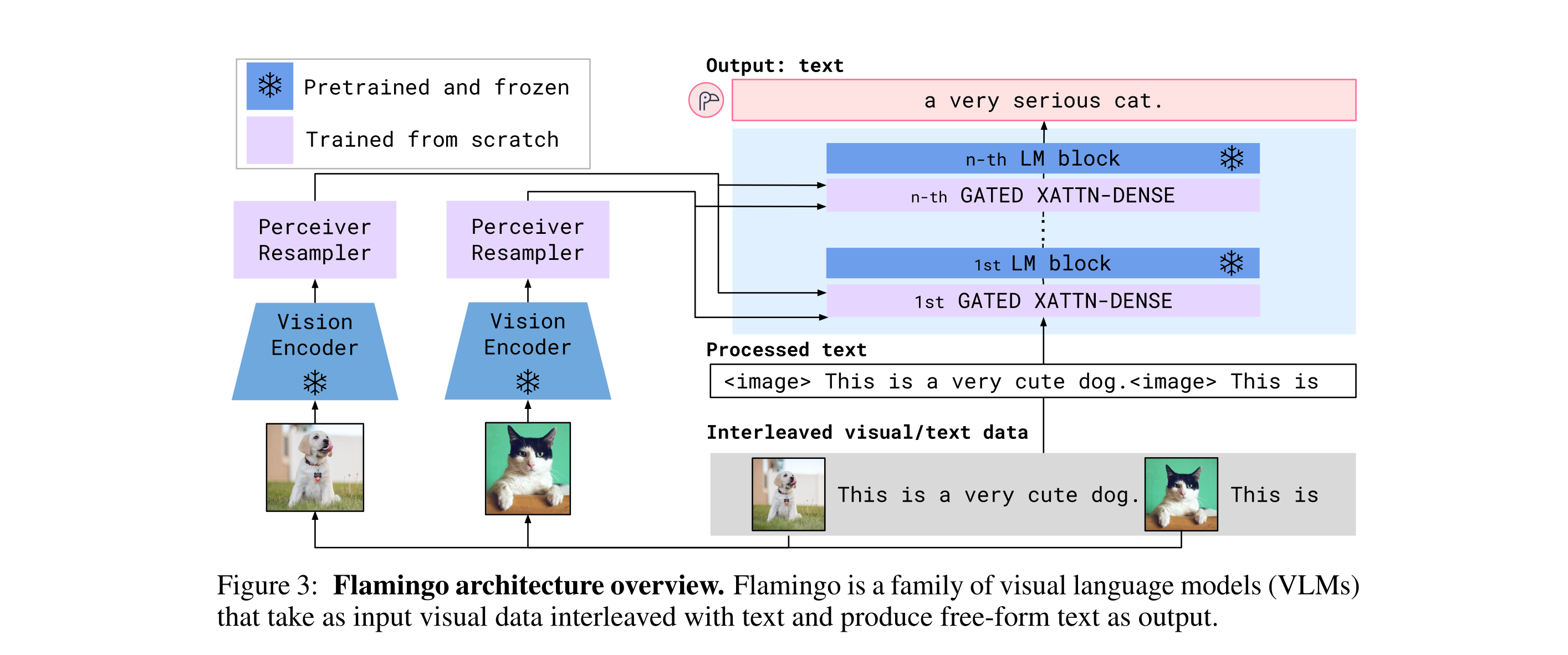
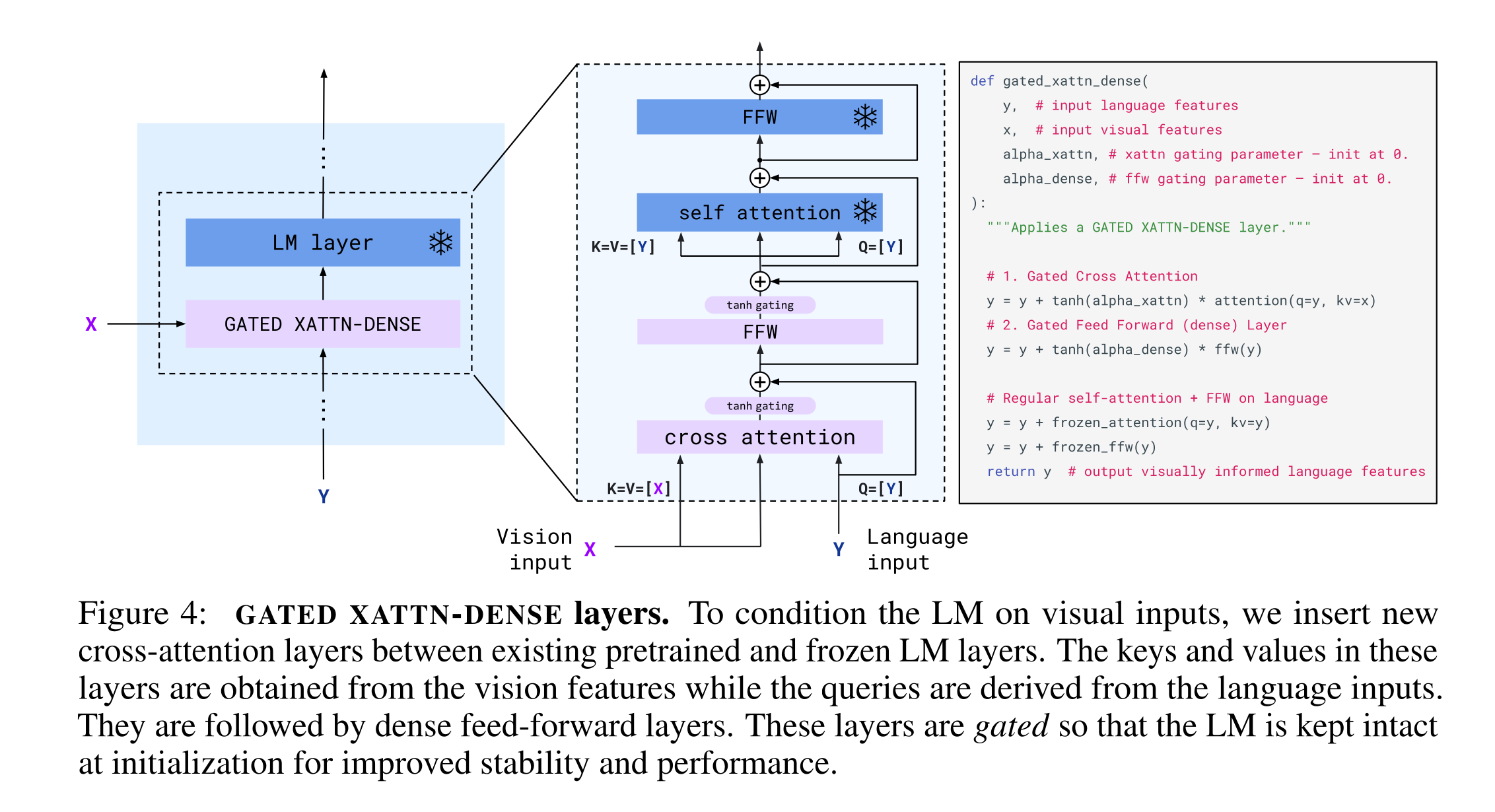
In more details …
Data collection:
- 43 million webpages. Sample a random subsequence of 𝐿 = 256 tokens and take up to the first 𝑁 = 5 images included in the sampled sequence
- For image text pairs,
- ALIGN [50] dataset contains 1.8 billion images paired with alt-text
- LTIP dataset consists of 312 million image and text pairs
- VTP dataset contains 27 million short videos (approximately 22 seconds on average) paired with sentence descriptions
- beam search for decoding
Evaluation
-
What can it do? It can learn to perform new task pretty quickly using “In-context learning” \ldots like what has been used in GPT3.
- Few shot learning: using only 4 examples
LLM knowledge retrieval

Setting: Given a dataset of text pairs (x, y), like x: question, y: answer.
Idea
- Model: Receive a sequence $x$, and output a prediction of sequence $\widehat{y}$
LLM contains knowledge somehow, and can be seen to have a parametric memory. Let’s extend that by adding a non-parametric external memory, in this case from Wiki. So given, for example, a question, model uses its internal knowledge, retrieve external resource, combine them and generate an answer.
More concretely, authors proposed a probabilistic model with 2 ways to do inference approximately: RAG-Sequence Model and RAG-Token Model,
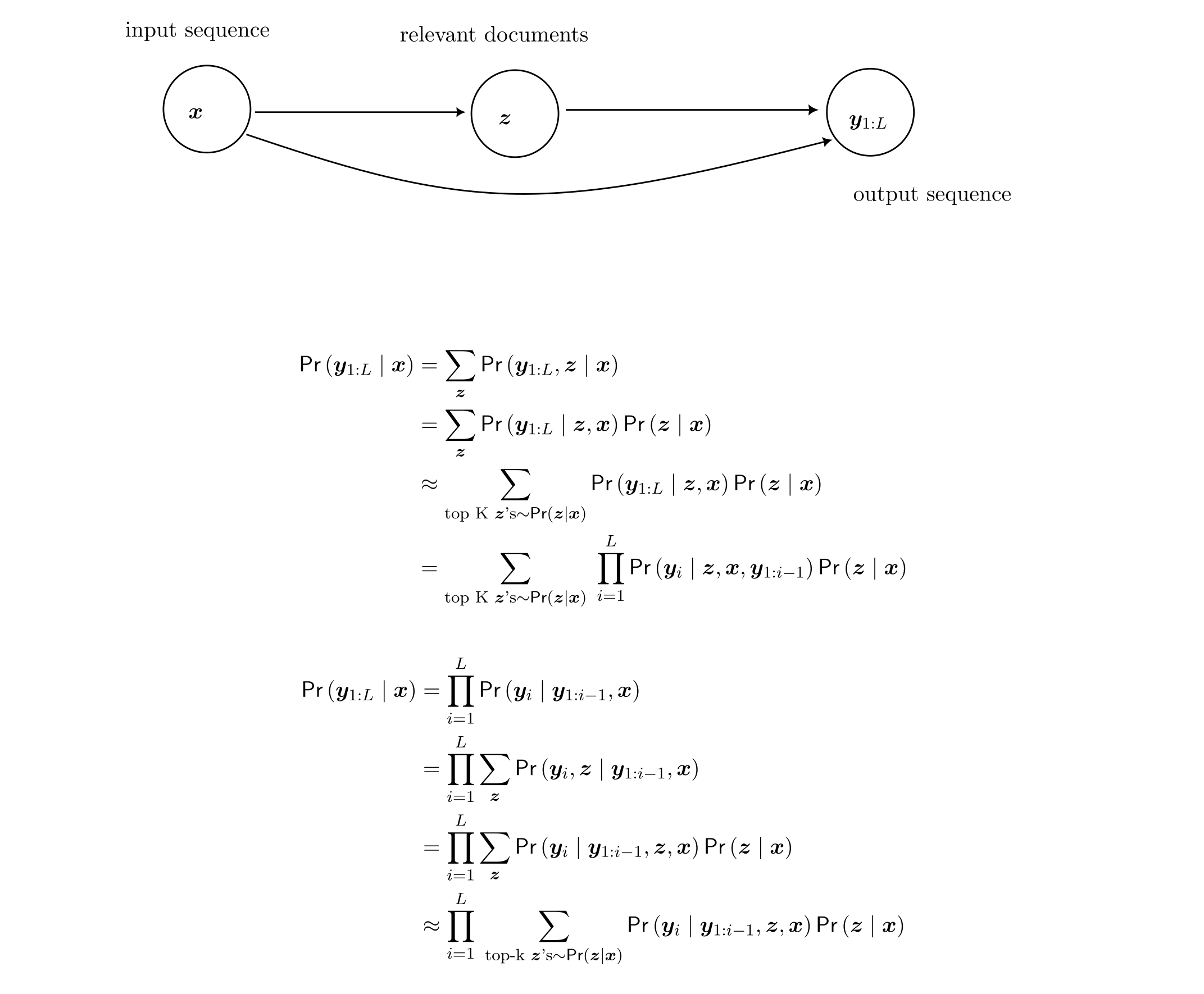
-
Dive in to the model architecture:
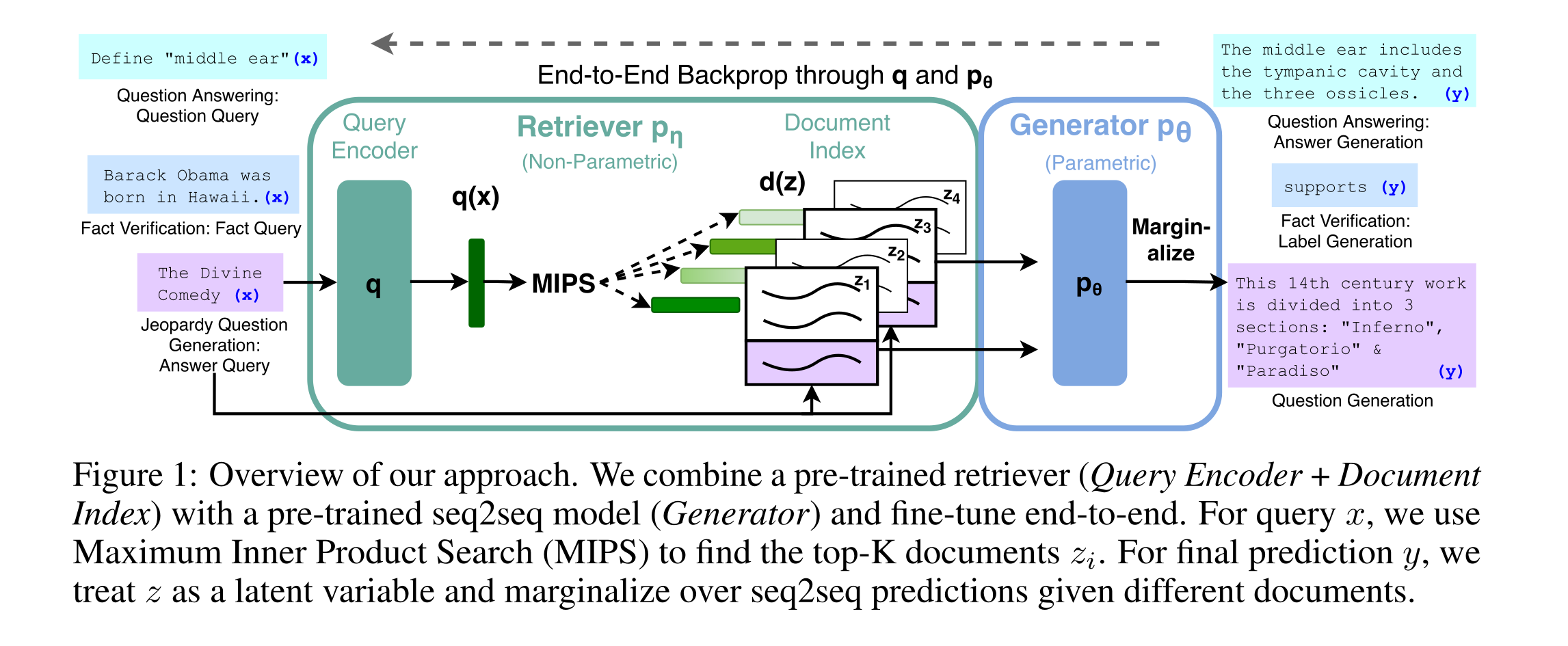

- The generator: BART-large, 400M parameters. Input is the concatenation of $x$ and top-k latent documents $z$. This BART-large model is accountable for ‘parametric memory’.
-
Train both Query encoder and Generator. Training objective is marginal log-likelihood of the target like usual, like in sequence generation.
Thoughts?
- Knowledge vs overfitting?
- What could be extended?
- Offer evidence like in Bing.
- Instead of using Wiki, get top 5 articles from Google search, input them to the BERT decoder. Or in general, hot-swap memory? Why do they have to replace the whole Wiki instead of substituting relevant articles?